Multi-Modal Streaming 3D Object Detection
Modern autonomous vehicles rely heavily on mechanical LiDARs for perception. Current perception methods generally require 360° point clouds, collected sequentially as the LiDAR scans the azimuth and acquires consecutive wedge-shaped slices. The acquisition latency of a full scan (~ 100ms) may lead to outdated perception which is detrimental to safe operation. Recent streaming perception works proposed directly processing LiDAR slices and compensating for the narrow field of view (FOV) of a slice by reusing features from preceding slices. These works, however, are all based on a single modality and require past information which may be outdated. Meanwhile, images from high-frequency cameras can support streaming models as they provide a larger FoV compared to a LiDAR slice. However, this difference in FoV complicates sensor fusion. We propose an innovative camera-LiDAR streaming 3D object detection framework that uses camera images instead of past LiDAR slices to provide an up-to-date, dense, and wide context for streaming perception. The proposed method outperforms prior streaming models on the challenging NuScenes benchmark in detection accuracy and end-to-end runtime. It also outperforms powerful full-scan detectors while being much faster. Our method is shown to be robust to missing camera images, narrow LiDAR slices, and small camera-LiDAR miscalibration.
A full LiDAR sweep is composed of a stream of slices/packets collected sequentially as the LiDAR scans the azimuth. Modern 3D detectors must wait for a full LiDAR scan (~ 100ms) before inference which presents a bottleneck for perception latency. This delay can lead to outdated detections which is detrimental to safe autonomous driving as shown below.

Instead of waiting for a full scan, streaming perception models take a LiDAR slice (once it arrives) as input. A LiDAR slice provides narrow 3D contextual information and may only contain a fragment of an object. To tackle this challenge, prior streaming works have utilized memory mechanisms and features from past slices to provide a wider global context.
Due to the dynamic nature of autonomous driving, past features may not be an honest representation of the current state of the world especially at high speeds for the ego-vehicle or other dynamic objects of interest.
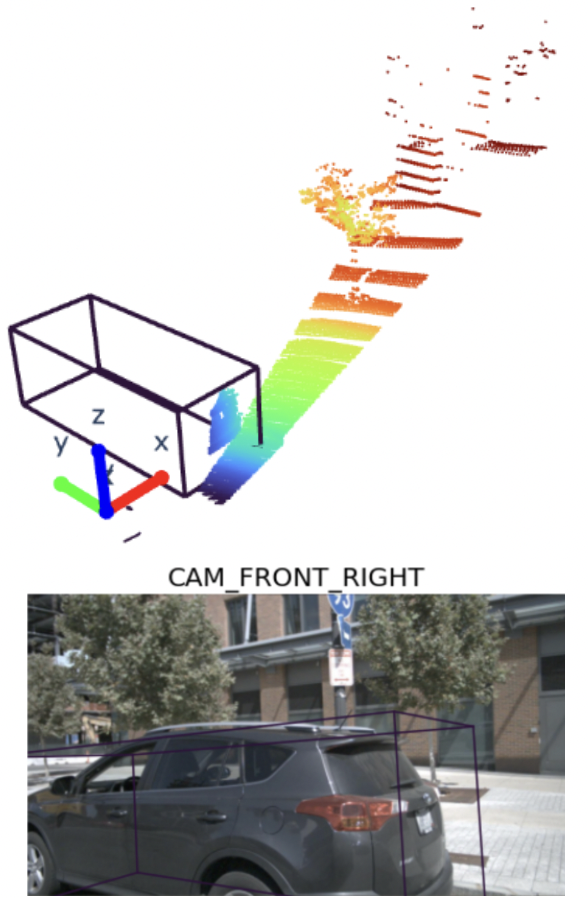
Instead of using past features, we propose to expand the narrow LiDAR context with up-to-date image features coming from high frame-rate cameras. Camera images also provide a wider FoV than a LiDAR slice, which makes them ideal in providing a global context for streaming detection. In the example above, a heavily fragmented vehicle in a very narrow 11.25° LiDAR slice is accurately detected in 3D using our fast multi-modal streaming framework.
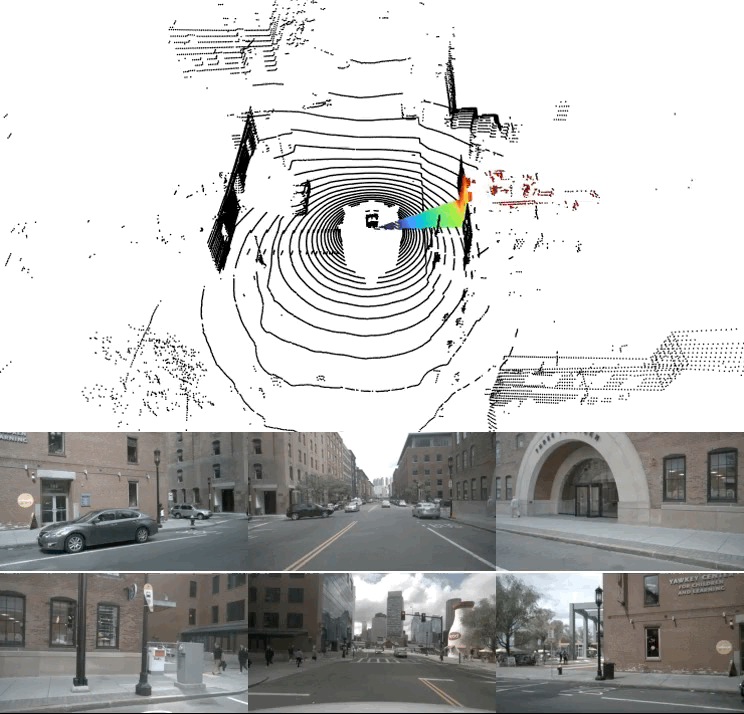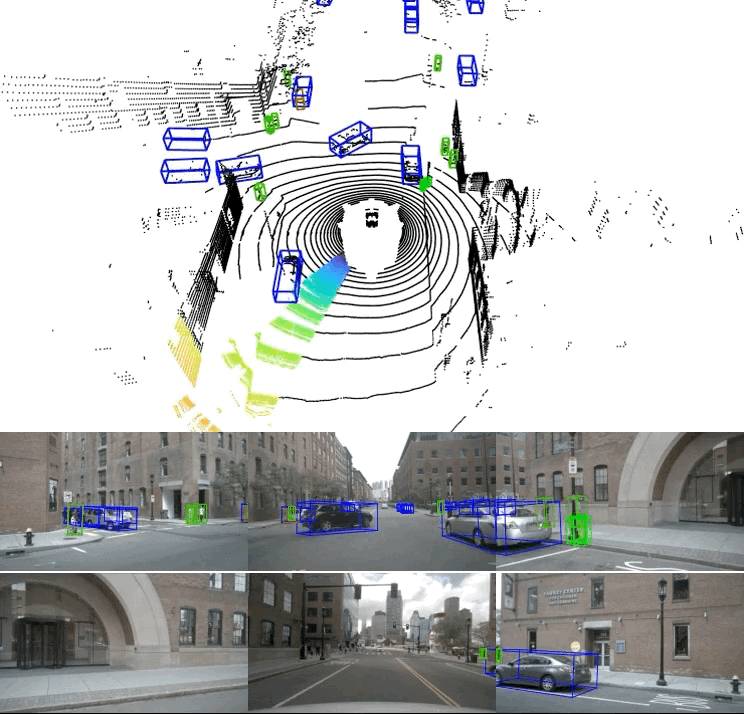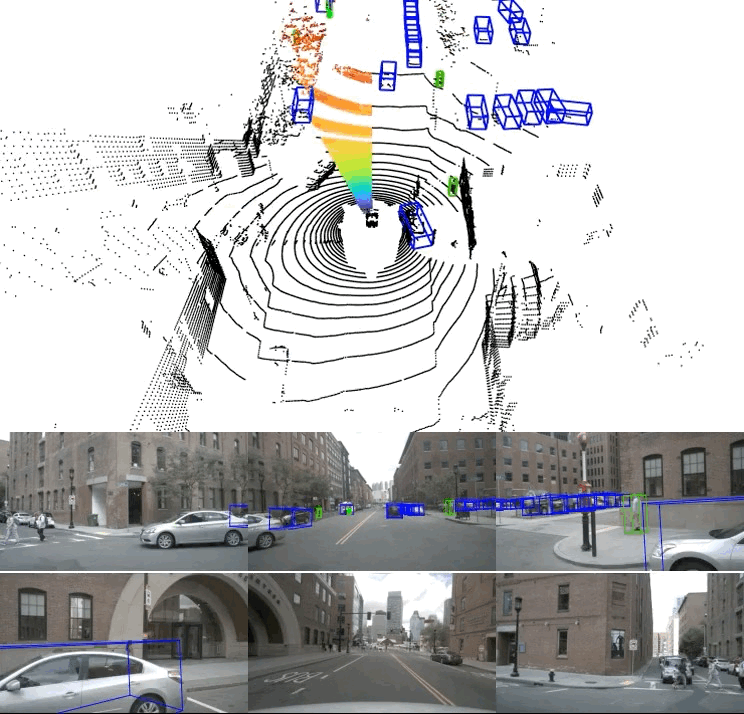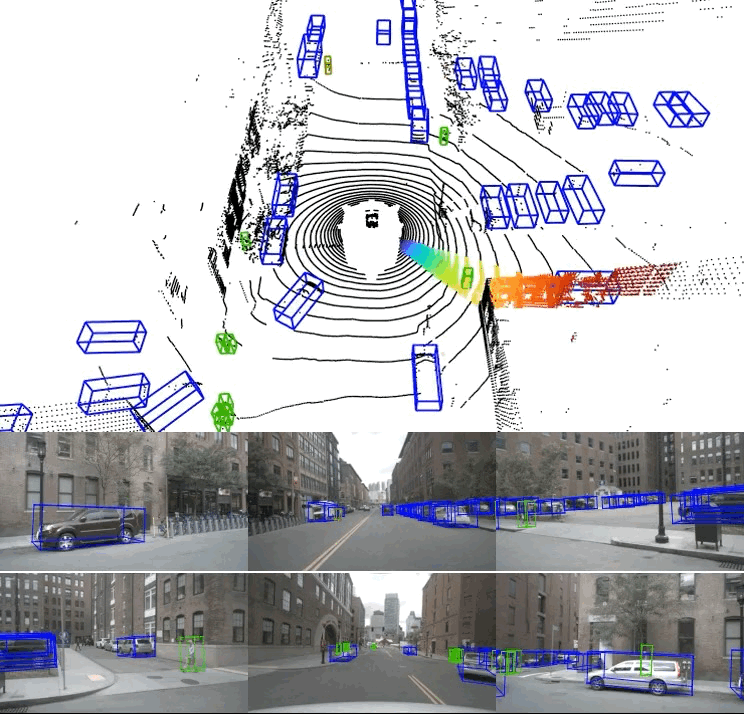
Our streaming framework takes a LiDAR point cloud slice (in this example a 45° slice) and its corresponding image(s) as input (see cars and pedestrian). These two modalities are then 3D-encoded separately and in parallel, then flattened to produce two top-down BEV feature maps. These features are then fused and sent to a BEV encoder and a detection head to produce 3D detections in a streaming fashion.
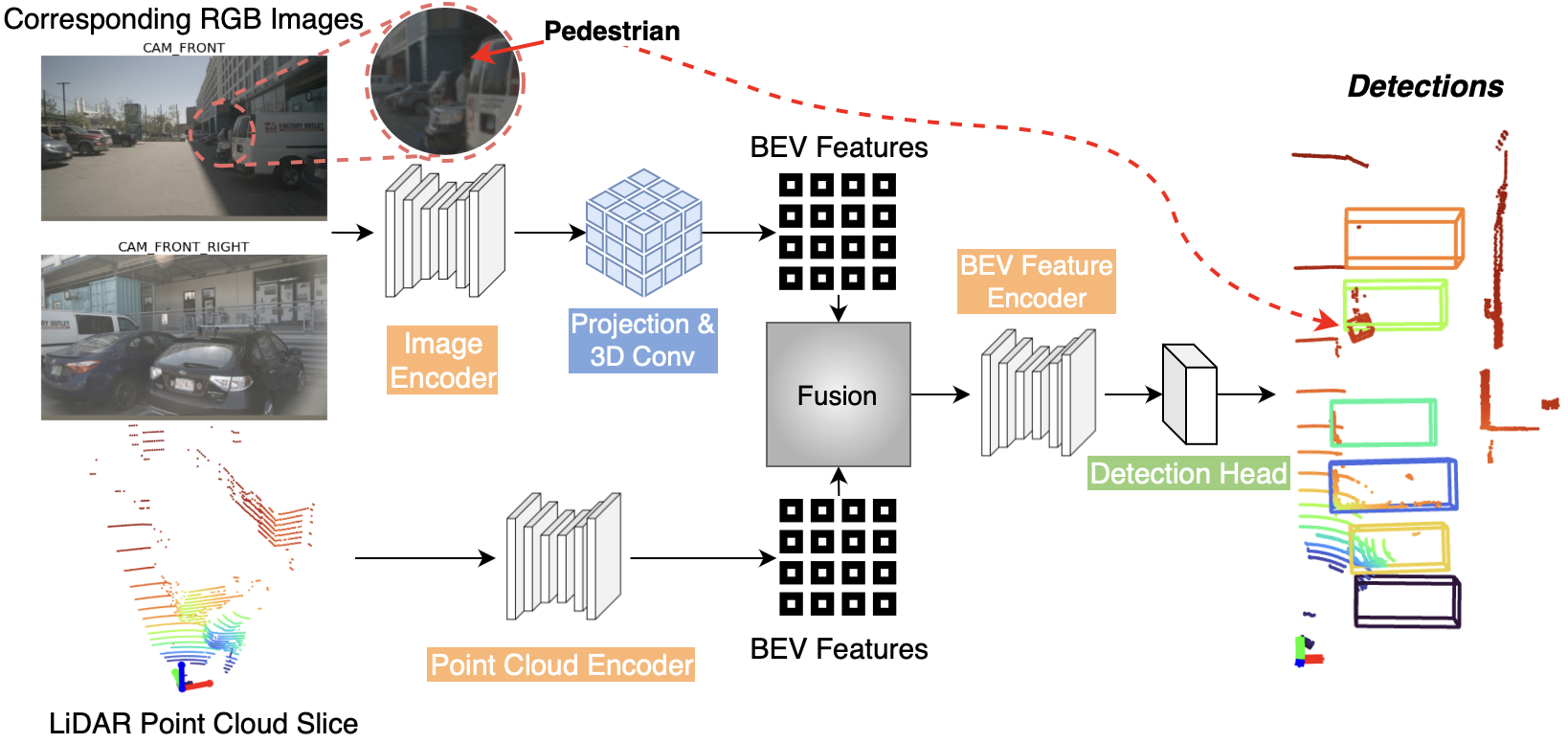
The example above shows the importance of the complimentary and spatially-related multi-modal feature maps: Images provide the context needed to accurately detect the fragmented bottom vehicle (dark purple box) with its very few points, and the person is detected despite occlusion and shade with the support of the point cloud input.
Taking only an 11.25° slice of a full LiDAR scan and its corresponding image, our 32-slice model produces the following accurate 3D bounding box predictions (blue for cars, dark green for pedestrians) as shown below. Ground truth boxes shown in green.
Predictions of the 32-slice model
Predictions of the 8-slice model
Predictions of the 8-slice model
Our 8-slice model (45° of a full LiDAR scan) producing accurate predictions (shown in the point cloud input) without the back camera
This demonstrates the robustness of our streaming framework that the camera with the largest FoV (back camera) can be missing and our 8-slice model still produces accurate 3D bounding box predictions in this space using the limited point cloud input
This figure shows the effect of various degrees of noise in camera-LiDAR calibration on the performance of our method.
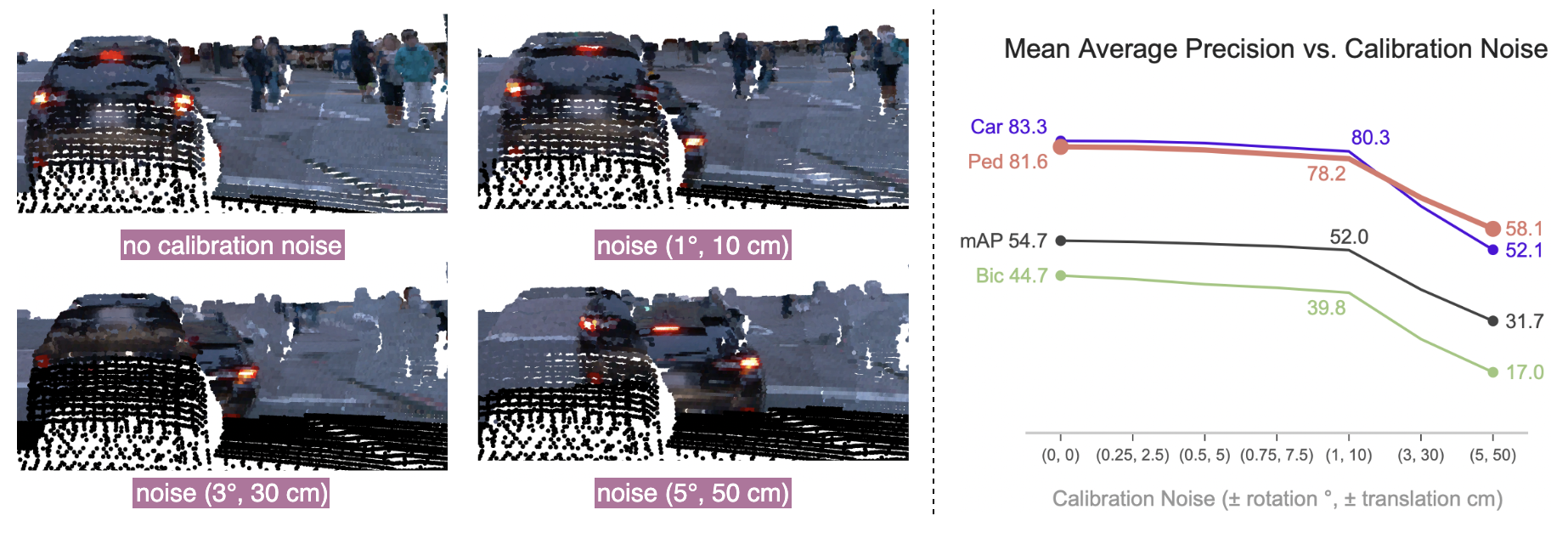
Left: Projection of an RGB image to 3D points with various degrees of noise. Even small noise completely disappears some pedestrians and corrupts vehicle points posing a critical danger to point-wise fusion methods. Right: Effect of the calibration noise on the mAP of our streaming 8-slice model.
@article{abdelfattah2023multi,
title={Multi-modal Streaming 3D Object Detection},
author={Abdelfattah, Mazen and Yuan, Kaiwen and Wang, Z Jane and Ward, Rabab},
journal={arXiv preprint arXiv:2209.04966},
year={2023}
}
The website template was borrowed from DreamBooth3D.